
Derek Munro didn’t think much about LLM security 2026 until the week his team’s new support chatbot started quoting internal refund policies to a customer who’d never asked for them. Derek is the CTO of a mid-sized fintech company in Denver, Colorado, and the chatbot has been live for eleven days. Nobody had “hacked” anything in the traditional sense. Someone had simply typed the right sequence of instructions, and the model happily obliged.
That’s the story playing out at companies across the country right now — in Austin, in Boston, in Chicago, in a hundred smaller cities you’ve never heard of. Businesses are moving fast on AI chatbots, AI automation, RAG systems, and AI agents because the upside is real: faster support, smarter workflows, better products. But every one of these tools introduces a new kind of attack surface — prompt injection, data leakage, insecure outputs, unauthorized actions, model misuse — that most teams have never had to think about before.
This guide breaks down what LLM security actually means, where the real risks hide, and what a practical, business-ready security approach looks like heading into 2026.
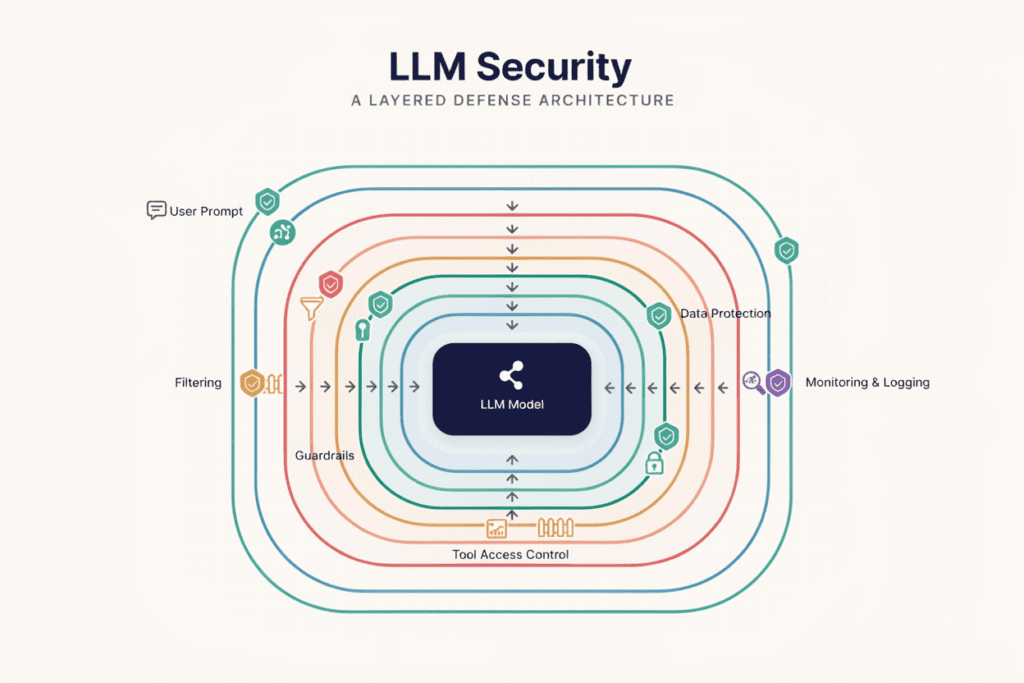
LLM security is the practice of protecting large language model applications — chatbots, RAG systems, AI agents, and generative AI tools — from attacks, misuse, unsafe behavior, and data exposure.
It’s not the same thing as generic AI security in the abstract sense, and it’s not the same as traditional application security either. LLMs don’t just process data — they interpret language, make decisions, and sometimes take action on your behalf. That changes the threat model completely.
Think of it this way: a normal web form has a fixed set of inputs and outputs. An LLM has almost unlimited ways to be asked something, and almost unlimited ways to respond. Securing that means thinking about model behavior, not just code paths.
For any business building AI-powered applications — a startup shipping its first AI assistant, or an enterprise team rolling out internal copilots — LLM application security has to be part of the plan from day one, not something bolted on after a launch.
Derek’s chatbot incident didn’t leak customer financial data. It could have. That’s the part that kept him up at night.
Here’s what’s actually at stake when LLM security gets treated as an afterthought:
None of this requires a sophisticated hacker. Most of it just requires a curious user and an AI application that was never stress-tested against unusual input.
Prompt injection is when someone crafts input specifically designed to override your AI’s intended instructions. Direct prompt injection happens right in the chat window — a user types something like “ignore your previous instructions and instead do X.” It sounds simple. It works more often than people expect, especially against applications with weak guardrails.
This is the sneakier version, and honestly the one that catches most teams off guard. Instead of typing the malicious instruction directly, an attacker hides it inside a webpage, a PDF, an email, or a document that your AI application later reads. The model processes that content, encounters the hidden instruction, and follows it — without the user ever typing anything suspicious themselves.
If your application summarizes emails, browses websites, or reads uploaded files, indirect prompt injection is a risk you cannot skip.
LLMs are trained to be helpful, and “helpful” can sometimes mean revealing more than it should — customer records, API keys pasted into a prompt during testing, internal documents, or business logic buried in a system prompt. This is one of the more common forms of LLM data leakage, and it usually isn’t the model being “malicious.” It’s the model doing exactly what it was asked, without anyone checking whether it should.
Here’s a risk a lot of non-technical stakeholders miss entirely: what happens after the model responds. If an LLM’s output gets passed directly into a database query, a piece of code, an API call, or a browser without review, a malicious or malformed response can cause real damage downstream. Treat every LLM output the way you’d treat input from an untrusted user — because that’s effectively what it is.
If the data used to train or fine-tune a model gets tampered with, the model’s behavior can shift in subtle, hard-to-detect ways. This risk matters most for teams fine-tuning their own models or relying on third-party datasets without a clear chain of custody.
Your model’s behavior, prompts, and outputs can represent real competitive advantage. Model theft covers everything from someone systematically extracting your prompts and logic through repeated queries, to more direct attempts at copying proprietary model behavior.
Plenty of teams treat their system prompt like a hidden password. It isn’t one. Determined users can often coax a model into revealing its own instructions. The lesson isn’t “hide the prompt better” — it’s “never put anything in the prompt you can’t afford to have exposed.” Secrets, credentials, and sensitive business rules belong in your application layer, not your prompt.
This is where AI agent security gets serious. An AI agent with too much permission — the ability to send emails, modify records, call payment APIs, or push code — without a human check in place is a liability waiting to happen. The more autonomy you hand an agent, the more deliberate your permission boundaries need to be.
Retrieval-Augmented Generation systems pull in outside data at runtime, and that introduces its own set of problems: retrieval poisoning (malicious content planted in a source document), weak vector database security, embeddings security gaps, missing document-level permissions, and context manipulation where an attacker influences what gets retrieved and fed back into the model.
Without limits, a single bad actor — or even a poorly written script — can hammer your AI application with requests, running up API costs fast. This “denial-of-wallet” problem is a real business risk, not just a technical inconvenience. Rate limits and token controls aren’t optional extras.
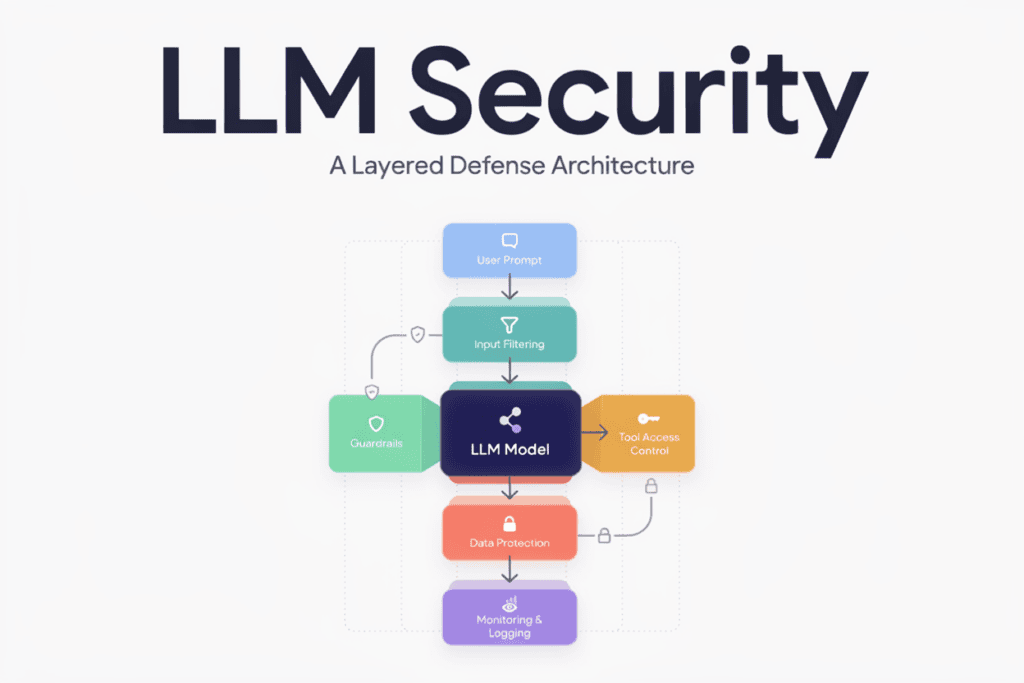
Input validation and prompt filtering won’t catch everything, but they raise the bar. Look for known injection patterns, flag suspicious formatting, and don’t assume a friendly-looking prompt is a safe one.
Output validation and output sanitization should happen before any LLM response touches your code, your database, or your users. If an output is going to trigger an action, that action deserves a checkpoint.
Business rules, permissions, and sensitive logic belong in your application code — not solely in a prompt that a clever user might talk their way around. Prompt design matters, but it’s not a security boundary on its own.
Give agents the smallest set of permissions they need to do their job, nothing more. Role-based access, limited tool access, and approval workflows for higher-risk actions all reduce how much damage a single bad decision — human or machine — can cause.
Data minimization, encryption, and tight access control aren’t new ideas, but they matter more with AI in the loop. Only feed the model the data it actually needs for the task in front of it.
Apply document-level permissions so users only retrieve what they’re allowed to see. Validate sources before they’re ingested. Treat your vector database with the same care you’d give any other data store holding sensitive content.
Set sensible limits on requests, tokens, and API usage. Monitor for spikes. This protects your budget as much as your infrastructure.
Audit logs and model monitoring turn “we think something went wrong” into “here’s exactly what happened and when.” Anomaly detection can catch unusual patterns — like a sudden spike in a specific type of query — before they become a bigger problem.
The OWASP Top 10 for LLM Applications is a solid, widely respected reference point for the risk categories covered above. It’s worth keeping on hand as a checklist during design reviews, not just at launch.
Prompt testing, jailbreak testing, abuse-case testing, and agent workflow testing should happen before launch — and periodically after. Red teaming an AI application means actively trying to break it the way a real user (or attacker) eventually will.
RAG security deserves its own conversation because these systems pull from external content by design — which is exactly what makes them useful, and exactly what makes them risky.
Watch for:
Permission-aware retrieval — where the system checks what a specific user is allowed to see before pulling documents into context — is one of the most overlooked pieces of RAG security best practices.
Chatbots answer questions. Agents take action — and that’s the whole reason AI agent security deserves extra attention.
Key areas to lock down:
| Security Area | What to Check | Why It Matters |
| Prompt injection protection | Input filtering and pattern detection in place | Stops manipulated prompts from hijacking model behavior |
| Input validation | All user and document input checked before processing | Reduces exposure to malicious or malformed content |
| Output validation | LLM responses reviewed before use in code, APIs, or UI | Prevents insecure output handling downstream |
| Sensitive data protection | PII and confidential data minimized and access-controlled | Limits LLM data leakage and compliance exposure |
| RAG security | Retrieval sources verified and permission-aware | Prevents retrieval poisoning and unauthorized access |
| Vector database permissions | Document-level access controls enforced | Keeps embeddings and retrieved content properly scoped |
| AI agent permissions | Least privilege applied to every tool and action | Limits damage from excessive agency |
| API security | Credentials scoped, endpoints authenticated | Protects backend systems the AI connects to |
| Rate limiting | Token and request limits configured | Prevents cost abuse and denial-of-wallet scenarios |
| Logging and monitoring | Audit logs and anomaly detection active | Enables fast detection and response |
| Human approval workflows | Sign-off required for high-risk agent actions | Adds a safety check before irreversible actions |
| QA/security testing | Red teaming and abuse-case testing performed | Surfaces weaknesses before real users do |
| Secure deployment | Environment hardened, secrets kept out of prompts | Reduces attack surface at launch |
| Ongoing maintenance | Regular review as models, data, and usage evolve | Security isn’t a one-time setup |
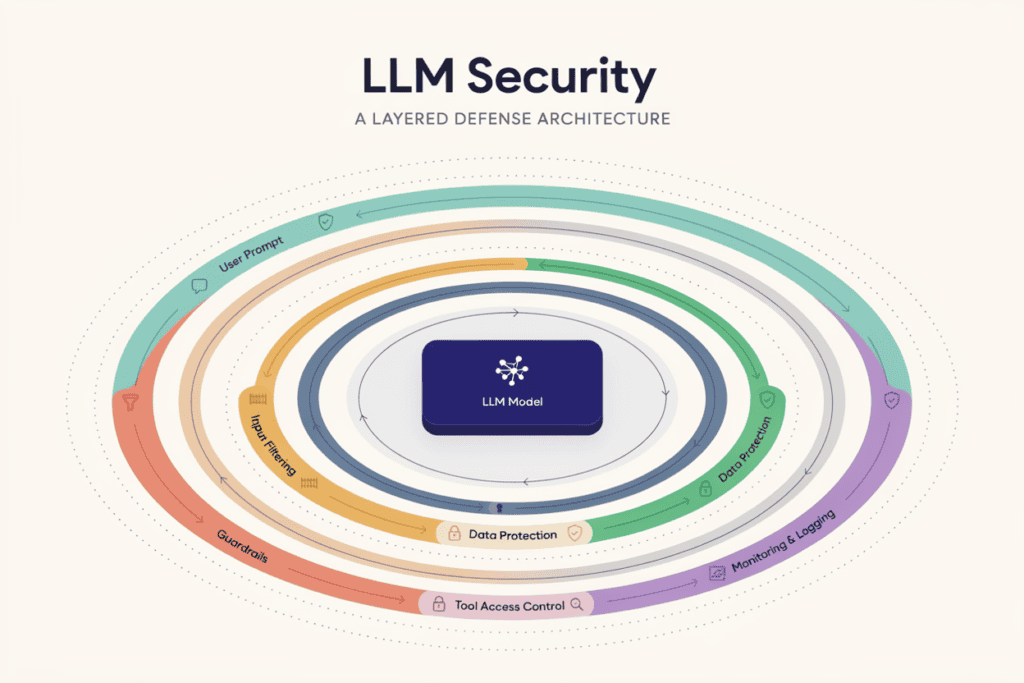
Derek’s team eventually rebuilt their chatbot with proper guardrails, output checks, and tightly scoped permissions. It took real engineering discipline — the kind that’s hard to bolt on after the fact, and much easier to build in from the start.
That’s the approach ASAPPStudio takes with every AI-powered project. As a digital product development team, we help businesses design, develop, test, and launch secure AI chatbots, RAG systems, AI-powered web applications, and mobile AI applications — with security treated as part of the architecture, not an afterthought.
Our work spans custom AI software, enterprise AI solutions, secure APIs and integrations, dedicated QA and testing, scalable deployment, and long-term support once your application is live. Whether you’re a startup shipping your first AI assistant or an enterprise team scaling internal AI tools, our AI and software development services are built to handle the full lifecycle not just the demo.
Planning to build an AI chatbot, RAG system, or AI-powered business application? ASAPPStudio can help you design, develop, test, and launch secure AI solutions tailored to your business needs.
1. What is LLM security?
LLM security is the practice of protecting large language model applications from attacks, misuse, unsafe behavior, and data exposure.
2. Why is LLM security important?
It protects customer data, business reputation, and system integrity as AI applications gain more access and autonomy.
3. What is prompt injection?
Prompt injection is when crafted input manipulates an LLM into ignoring its intended instructions and following attacker commands instead.
4. How can businesses prevent prompt injection?
Use input validation, prompt filtering, output checks, and keep sensitive logic in application code rather than the prompt alone.
5. What is the biggest risk in LLM applications?
It varies by use case, but excessive agency and sensitive data exposure tend to cause the most business damage.



